Hi I have a feature to bulk upload 200K of customer records to an external system. Let me describe the flow.
Call a logic block endpoint (perhaps a background-task logic block?) to create a batch_process table to keep track each of the 100K customers for keeping the process status of each customer.
Loop until done
Fetch 100 customers and then send them in one request to the external system via an outbound endpoint
One question is that the request mapping might be tricky here since it would be an array of up to 100 customer objects. As I recall, the outbound request and response mapping are pretty much flat field mapping. In this case, would might have to 100 sets of data items :-(.
Update the batch_process table with success or failed status for those 100 customers
Handle error accordingly.
Tell the external system that it is all done
I was looking into the Queue Parallel Processing action that I can use in the logic block builder. I have some questions:
Can we set the maximum number of parallel buckets? For example, the external system could handle only 5 concurrent requests to receive the customer records in batch.
Would it work for a big table with 100K records? In particular, would it cause a transaction timeout?
How robust is error handling? If an error occurred, would it abort the entire processing?
Also, questions on Background-Task Logic Block:
Does it mean it is an async/nonblocking action and would not block the calling thread?
Can it be referred to as a logic block endpoint?
e.g. /v2/LogicBlocks/{background-task-logicBlock}:executeWithSignatures
Your general strategy seems sound to me, and using parallel processing would speed things up I expect. Answers to specific questions
JSON structures can be built dynamically, where a large array can be constructed while looping a set of records. More details on this are in a Release Note that went out with 24.2 called Complex JSON Request & Response Handling
Not as far as I’m aware right now. You get 8 whether you like it or not.
Yes, it would work and would need to run for a very long time to time out (I can’t remember what the timeout is for background tasks right now)
If you modularize the logic and an error is thrown in a called logic block that would normally interrupt processing, if the calling logic block has configured the call to have Adopt All Messages flag set to False, it will add the error to a message list instead of itself interrupting. This is how we typically do large batch processing is move the errors into a called logic block configured this way and then expose the messages for the records that failed in some type of log and let the rest of the records complete successfully.
I’ll need you to clarify what you’re asking here probably using Nextworld familiar terminology.
You can initiate background tasks via an inbound endpoint call this way, yes.
What I meant is that I want to call that background-task logic block that would call the Queue Parallel Process action. Because the parallel processing would take an hour, I need to avoid having the caller to the background-task logic block to wait for the entire process to complete.
Would it be a best practice to have the caller to invoke a logic block A that invokes a Queue Background Logic Block action, which would have the logic to invoke the Queue Parallel Processing action? In this case, logic block A would call the Queue Background Logic Block action, which would invoke the associated background-task logic block in the background, and logic block A will then return to the caller without waiting for the background task to complete?
Example:
1. LB A –> LB B (Background-task LB associated with the Queue Backgorund Logic action)
2. LB B queued and control returns to LB A
3. LB A returns to caller
4. LB B runs
a. create the initial batch_process_status table and
b. invoke LB C (the Queue Parallel Processing action) ...
c. LB C completes the parallel processing finally
In this flow, LB B would be queued up and return to LB A immediately to continue invoking other actions in A.
For the first point I amended my original response to be Yes, it would work and would need to run for a very long time to time out (I can’t remember what the timeout is for background tasks right now)
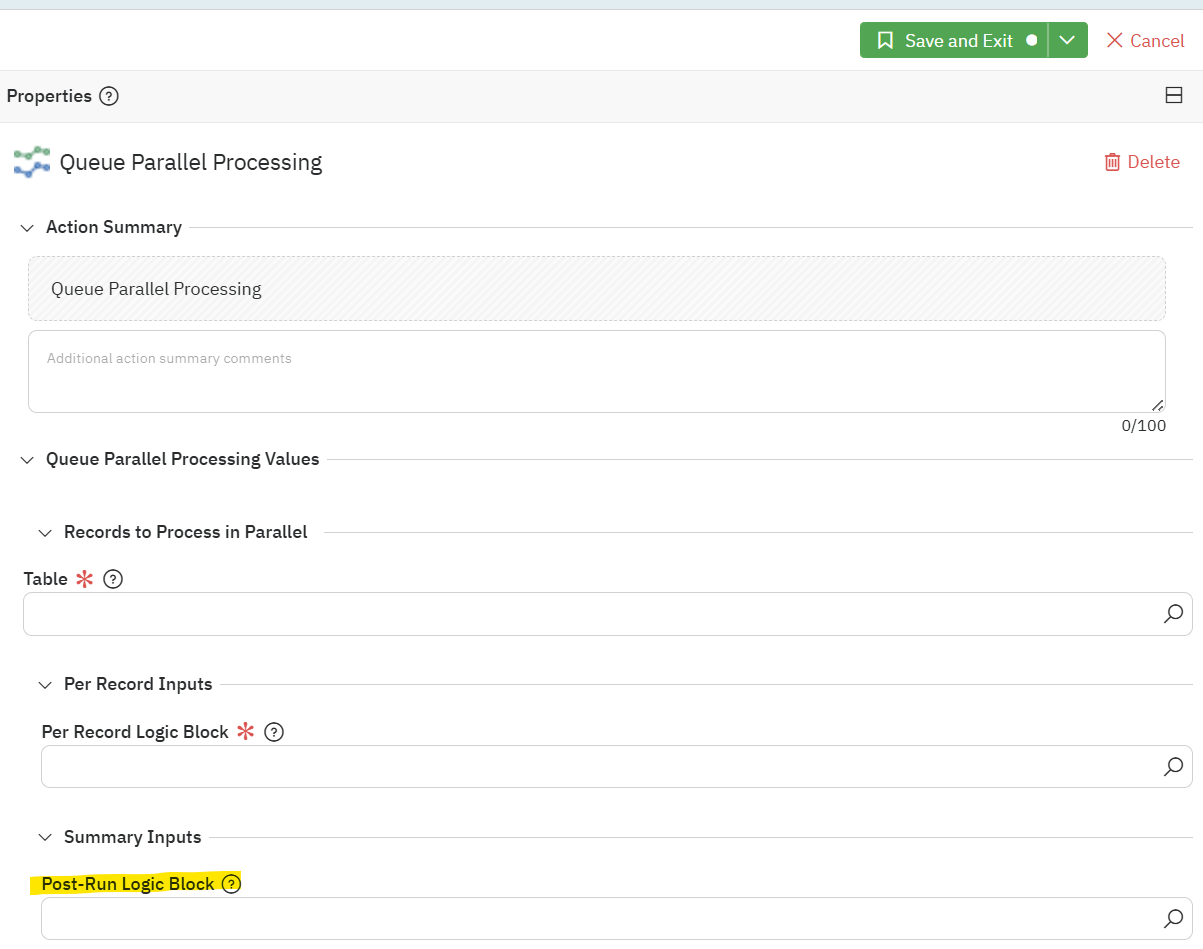
For the second point, I’m not sure I fully understand yet, and we may want to meet to discuss this, but it sounds like you may be wanting to configure aPost-Run Logic Block which will be responsible for doing whatever needs to be done after all the parallel processing jobs have completed? Rather than have whatever process kicked off the parallel jobs have to wait around for an unknown amount of time.
Ian would the streaming endpoints concept not be helpful here? I recall it was in development but may have been reverted?
If we construct API calls with multiple objects being passed to the CC API, what field can we use to group the records when setting up a background logic block with parallel processing? Could we use the same fields that are used during the bulk import into NW?
I’m confused by the ask, it’s too abstracted for me to understand what you’re trying to do and what the behaviors need to be. Please book time with me to discuss further: Bookings with me
One additional note here - it is possible to prevent parallel processing from running in 8 separate buckets.
When a job begins running in parallel, the system will determine how many buckets should be used based off of how many records are processing and the unique identifiers of those records. By using the Distinct Fields and Bucket Fields attributes of the Queue Parallel Processing action, you can dictate which records should be processed in the same or different groups. If you amend the data set to include ~40k records in five separate groups (by number, type, or something else), you can force the parallel processing to occur only in five buckets instead of the full 8.
Meeting was held yesterday on this. Working proposal that leverages Parallel Processing that I took away, explained in an inside-out fashion:
The crucial question ends up being how many records should be processed at a time by the Per Record Logic Block. Options considered were:
1 record per logic block call
100 records per logic block call
the whole bucket of 25,000 per logic block call
1 doesn’t make sense as you want to process 100 records at a time. 25,000 has other drawbacks discussed next, so the preferred scope of the per-record logic block is for it to process 100 at a time
Parallel processing is designed to support this situation by specifying a Distinct Fields where the distinct field identifies each batch of 100 records to be processed. This requires some preprocessing to assign the records a batch number
To do this, prior to executing this process, in a ‘staging’ table that is similar to a Nextworld inbound integration table, create data that identifies which records are going to be exported and gives them batch numbers. Using a batch size of 100, there would be 2,000 discrete batch numbers. Split among 8 buckets for parallel processing, this is 250 batches / 25,000 records per bucket.
When pushing the data outbound, use Queue Parallel Processing with a Distinct Fields set to the Batch Number field. This should cause each batch of 100 records to be processed using a single call of the Per Record Logic Block. The reason for doing this is, if the parallel processing job runs into issues and needs to restart or be adopted and its bucket has already processed 81 of 250 batches and runs into issues on batch 82, it can restart from batch 82 and not have to go back to the beginning which is what it would do if the per-record logic block processed the entire bucket of 25,000 records.
Streaming Endpoints is a feature that is internal to the Nextworld platform. When Nextworld makes an endpoint request to another system, the response request can be large and was previously handled in a way that was memory intensive and subject to a 15,000 row limitation. This feature overhauled that mechanism to stream the endpoint response request out of Nextworld. This feature is purely about handling the data that is inbound outbound from Nextworld as part of a response request that Nextworld has made of some other system.
It was intended to go live as part of the 23.2 release, but ran into several complex regressions which affected some partners who were heavy users of outbound integrations. My recollection is those were fixed and it was fully stable as of the 24.1 release.